Informacje podstawowe
Biometryka bazująca na kodzie DNA znalazła uznanie w środowisku naukowców, rządowym a także opinii publicznej jako stabilny biometryk, o teoretycznie większych możliwościach od najbardziej rozpowszechnionego do tej pory odcisku palca. Identyfikacja na podstawie unikalnej, mierzalnej a jednocześnie stabilnej charakterystyki genetycznej osobnika rozwijała się szybko w ciągu ostatnich dwóch dekad. Kod DNA (który można pobrać w bardzo różny sposób) wydaje się również być bardzo dokładnym biometrykiem, jeżeli badanie zostanie przeprowadzone prawidłowo (główne problemy to możliwe zanieczyszczenie próbki oraz ich zastępowanie).
Skrót DNA rozwija się jako „kwas deoksyrybonukleinowy”. DNA jest unikalną i możliwą do analizy cechą ludzką, powszechnie uznawaną przez społeczeństwo za jedyny konieczny dowód identyfikacji. W rzeczywistości tego typu badanie nie jest niepodważalne, ale jest jedynym o prawie idealnej skuteczności określanej na ok. 99,999%. Struktura chemiczna DNA każdego człowieka jest taka sama. Jedyna różnica pomiędzy ludźmi leży w sekwencji podstawowych par. U każdego osobnika występują ich miliony. Na podstawie kolejności ich występowania można rozpoznać danego człowieka. Ponieważ analiza wszystkich tych par nawet u jednego osobnika byłaby bardzo pracochłonna naukowcy skupiają się na niewielkiej ilości par, co do których wiadomo, że różnią się one w znacznym stopniu pomiędzy ludźmi.
W kodzie DNA zawarte są informacje genetyczne żywych organizmów. Ma ono strukturę dwóch łańcuchów, odkrytych przez Jamesa Watsona oraz Francisa Cricka w 1953 roku. Każdy łańcuch ma liniową strukturę składającą się z czterech rodzajów nukleotydów: A – adeniny, G – guaniny, C – cytozyny oraz T – tyminy.
Trzeba też wziąć pod uwagę, że tylko dwa typy połączeń są tutaj możliwe mianowicie adenina(A) zawsze łączy się z tyminą(T) natomiast guanina(G) z cytozyną(C). W związku z tym oba łańcuchy wzajemnie się uzupełniają, jeśli na przykład pierwszy zawiera sekwencję CCTTAGATCA to drugi będzie wyglądał tak GGAATCTAGT. Taka sekwencja par określa wszelkie cechy genetyczne danego człowieka.
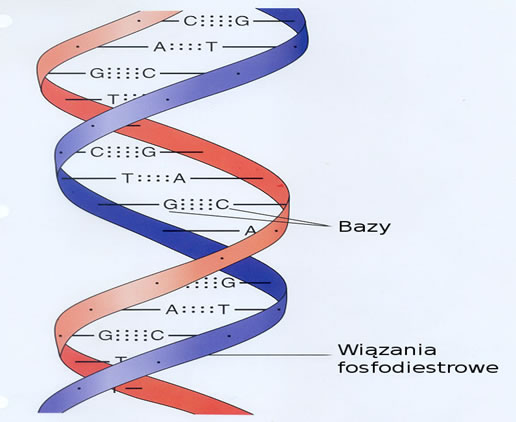
Rys 3.1 Łańcuch DNA
Źródło: http://coledavid.com/wonders/wonders_modern.html
W praktyce identyfikacja DNA bazuje na pewnych regionach kodu, zwanymi regionami niekodowanymi molekuły DNA (nie zawierają żadnych informacji o konkretnych cechach osobnika). Próbkę do zbadania można pobrać z bardzo różnych źródeł takich jak: ślina, krew, mocz, włos, tkanka czy kość. Żyjąc na co dzień własnym życiem mimowolnie „rozsiewamy” nasz kod genetyczny, zostawiając go w miejscach w których przebywaliśmy. Przekształcanie takiej próbki we wzorzec jest procesem nieodwracalnym. Na podstawie takiego wzorca nie można poznać cech genetycznych lub medycznych danego człowieka, ponieważ technika ta skupia się na niekodowanych regionach łańcucha DNA, a konkretnie na regionach charakteryzujących się wysokim wskaźnikiem polimorfizmu (różnic u każdego człowieka).